Un bug critique frappe les RTX 5090 et RTX PRO 6000 en virtualisation
Mauvaise nouvelle pour les professionnels de la virtualisation et du cloud computing : les toutes nouvelles cartes graphiques NVIDIA RTX 5090 et RTX PRO 6000, basées sur l’architecture Blackwell, rencontrent un bug majeur dès qu’elles sont utilisées dans un environnement virtuel.
Quand la virtualisation brise les GPU
Le problème survient lorsqu’une machine virtuelle procède à un reset du GPU (via une Function-Level Reset). Dans ce scénario, la carte cesse purement et simplement de répondre. Le journal système affiche alors des erreurs du type :
- “not ready 65535 ms after FLR; giving up”
- “unknown header type 7f”
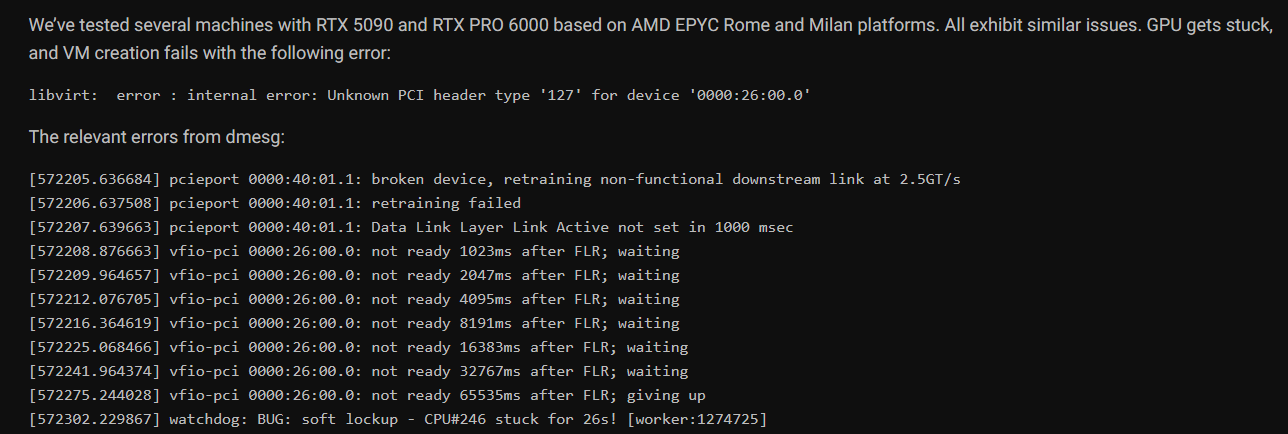
Source : tweaktown.com
Conséquence directe : le GPU disparaît du système, les machines invitées se bloquent, et parfois même l’hôte entier entre en soft lock. Le seul moyen de récupérer la main est un redémarrage complet du serveur, une opération lourde et particulièrement gênante dans des environnements où des dizaines de VMs tournent en parallèle.
Ce dysfonctionnement met en lumière une fragilité inattendue dans l’écosystème Blackwell :
- Instabilité critique en production – Impossible d’assurer des services continus sans risquer un arrêt brutal.
- Perte de confiance – Les nouvelles générations de GPU, censées apporter un gain de puissance, se retrouvent inutilisables dans certains scénarios pro.
- Coût d’exploitation accru – Chaque redémarrage non planifié engendre une perte de disponibilité et des interventions supplémentaires.
Ce bug touche spécifiquement les modèles :
- RTX 5090
- RTX PRO 6000
En revanche, d’autres GPU comme la RTX 4090, le Hopper H100 ou encore le Blackwell B200 semblent épargnés.
Le premier signalement a été fait par CloudRift, un fournisseur de GPU cloud, rapidement confirmé par des utilisateurs sur Proxmox et les forums Level1Techs.
La réaction de NVIDIA
Face à l’ampleur du problème, NVIDIA a reconnu le bug, affirmant avoir réussi à le reproduire en interne. L’entreprise travaille désormais sur un correctif, mais aucune date n’a encore été communiquée pour un patch ou une mise à jour de driver.
En attendant, certains administrateurs rapportent que l’usage de noyaux modifiés sous Proxmox (par exemple le 6.14.8-2-bpo12-pve) peut limiter les plantages… sans pour autant résoudre totalement la situation.
Une prime pour trouver un correctif
Pour accélérer la résolution, CloudRift a lancé une cagnotte de 1 000 dollars. La somme sera versée à celui ou celle qui découvrira une solution fiable ou un contournement efficace au bug. Une initiative qui témoigne de l’urgence de la situation pour les prestataires cloud et les entreprises déjà équipées de ces GPU.
L’affaire des RTX 5090 et RTX PRO 6000 montre à quel point un bug logiciel peut transformer un GPU haut de gamme en véritable casse-tête pour les administrateurs système. En attendant le correctif de NVIDIA, la prudence reste de mise pour les environnements virtualisés.
👉 Et vous, seriez-vous prêt à déployer ces GPU dans un cluster Proxmox ou dans une infrastructure cloud malgré ce risque ?
Partager cet article
Écrit par
larevuegeek
Commentaires (0)